
 |
| Nicolas Poussin, "La peste di Azoth" (1631), Louvre. |
L'idea di fondo è molto semplice: la popolazione viene suddivisa tra suscettibili (S), cioè individui sani che potrebbero contrarre la malattia, infettivi (I) che si sono ammalati e sono quindi veicolo della malattia, e "recovered" (R), cioè individui che sono "usciti di scena" perché guariti oppure deceduti o ancora messi in isolamento.
I due scienziati Kermack-McKendrick scoprirono che, sotto alcune ipotesi semplificative, gli individui possono passare soltanto dalla classe S alla classe I oppure dalla classe I alla classe R.
La sfida è capire come avvengano questi passaggi, cioè come possano variare nel tempo le numerosità delle tre classi epidemiologiche: in altre parole descrivere l'andamento delle funzioni S(t), I(t) ed R(t). Per riuscire nell'intento, dobbiamo pagare un piccolo prezzo: introdurre un po' di matematica nella nostra discussione.
Ma non temete: se mi seguite con un pizzico di pazienza arriverete sani e salvi alla fine. Con qualche utile nozione in più, almeno spero (intendiamoci, io non sono un epidemiologo o un virologo e nemmeno un medico, ma semplicemente un insegnante e un divulgatore matematico: l'obiettivo di questo post non è sostenere una o l'altra tesi in un campo nel quale non ho alcuna voce in capitolo, ma mostrare come anche in questo ambito è stata usata la matematica per formalizzare alcuni concetti).
Innanzitutto dobbiamo analizzare meglio i meccanismi alla base dei passaggi di classe che ho citato prima. Per esempio, cosa significa che un individuo passa da S a I? Be', semplice: il malcapitato si è infettato ed è diventato contagioso. Perché ciò avvenga, serve un incontro tra un infettivo e un suscettibile: il primo, essendo contagioso, trasmette la malattia al secondo.
La domanda che assilla ciascuno di noi in questi giorni di preoccupazione per il COVID-19 è: quanto è probabile che io contragga il virus? Il calcolo combinatorio e la teoria della probabilità possono darci una mano in questa stima. Supponiamo che N sia il numero totale di individui della popolazione: questo numero è costante perché, come abbiamo visto, Kermack e McKendrick trascurano le nascite e i morti per cause diverse dall'epidemia.
È facile dimostrare che, in una popolazione di N persone, il numero di incontri possibili tra due soggetti è pari a

Per esempio, se ci fossero in tutto N=5 individui (chiamiamoli Alberto, Beatrice, Carlo, Daniele ed Elena), il numero totale di possibili incontri sarebbe

Ma quanti di questi possibili incontri è a rischio? Basta che si tratti di un contatto tra un suscettibile e un infettivo: in questo caso è possibile (non certo) che il suscettibile venga contagiato. Il numero di incontri di questo tipo è dato dal prodotto tra il numero degli individui suscettibili S0 e il numero degli infettivi I0, ovvero da


Per esempio, se dei nostri N=5 individui, I0=2 sono già infettivi (poniamo Beatrice e Daniele) e gli altri S0=3 sono suscettibili, gli incontri a rischio sono S0I0=6 (Alberto-Beatrice, Alberto-Daniele, Beatrice-Carlo, Beatrice-Elena, Carlo-Daniele e Daniele-Elena) e la probabilità che uno di questi abbia luogo risulta essere uguale a

 |
| L'eremita dei tarocchi |
Se si verifica un incontro a rischio, non è detto che l'infettivo contagi il suscettibile: potrebbe accadere, certo, ma la persona ancora sana potrebbe avere fortuna e salutare l'infettivo senza aver preso il virus. Ovviamente dipende dalla contagiosità della malattia: indichiamo allora con α la probabilità che un incontro a rischio determini un contagio. Preso a caso un incontro tra due individui, la probabilità che questo risulti in una nuova infezione è uguale a




Abbiamo così determinato che se S(t) è il numero di individui suscettibili in un certo giorno t, il giorno successivo tale numero sarà diventato

Indichiamo con γ la percentuale di infettivi che ogni giorno passano nella terza classe epidemiologica per uno qualsiasi di questi tre eventi: allora, detto R(t) il numero di individui "recovered" in un certo giorno t, il giorno successivo tale numero sarà cresciuto secondo la relazione

E il numero di infettivi? Be', esso da una parte cresce in virtù dei contagi, ma dall'altra diminuisce per effetto di guarigioni, decessi e isolamenti. Il saldo totale è il seguente:

Queste tre equazioni costituiscono il modello SIR di Kermack e McKendrick in un'ipotesi discreta (perché abbiamo descritto il tutto in uno scenario che avviene "a scatti", anzi a giorni).
Se traduciamo questo sistema in forma continua, si ottiene facilmente questo bel sistema di equazioni differenziali:

Le strane "frazioni" poste nei primi membri di queste equazioni sono le derivate delle tre funzioni S(t), I(t) e R(t) rispetto al tempo, cioè le misure di quanto velocemente queste quantità variano al trascorrere del tempo.
Com'è facile intuire, tutto dipende dal gioco dialettico di quei due parametri β e γ: il primo ci fornisce un indice della contagiosità dell'agente patogeno, il secondo un indice della possibilità che un malato "esca di scena" in quanto guarito, deceduto o isolato.
 |
| Le tre classi epidemiologiche del modello SIR e i parametri che regolano il passaggio da una all'altra |
In particolare, la seconda equazione del sistema ci dice che la variazione del numero di infettivi
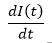
è determinata da un termine "positivo" proporzionale al prodotto S(t)I(t) secondo la costante di proporzionalità β e da un termine "negativo" proporzionale a I(t) secondo la costante di proporzionalità γ. Come si vede facilmente, questa variazione è positiva (cioè gli infettivi aumentano) se

cioè se il rapporto γ/β è minore del numero di suscettibili S(t).
Questo rapporto ha quindi il significato di soglia all'inizio dell'epidemia: se il numero di individui suscettibili è maggiore di questa soglia, l'epidemia può innescarsi e tenderà, in una prima fase, a espandersi in modo molto rapido; se invece è minore, l'epidemia non riesce nemmeno a partire perché il numero degli infettivi si estingue subito.
La buona notizia è che il numero di suscettibili, come abbiamo visto, diminuisce sempre: questo ci assicura che, anche nelle epidemie più devastanti, prima o poi esso scenderà al di sotto del rapporto γ/β, dando avvio alla fase discendente dell'epidemia. In alcuni casi, purtroppo, ciò avviene al prezzo di un elevato numero di vittime.
Concentriamoci ora sul caso "brutto", quello di vera epidemia: S(t) > γ/β.
Moltiplicando entrambi i membri di questa disequazione per β/γ si ottiene una relazione del tutto equivalente:

Quindi se l'inverso del rapporto di soglia moltiplicato per il numero di suscettibili è maggiore di uno, l'epidemia si innesca, altrimenti no. All'inizio dell'infezione, il numero di suscettibili è uguale a N, perché ancora nessuno si è contagiato. Se potessimo fotografare la situazione in quel momento e quantificare il numero


Guardate la tabella qui a fianco. Il morbillo, per esempio, un tasso netto di riproduzione altissimo, che può arrivare addirittura a 18 persone contagiate in media da un singolo malato. Altre malattie risultano meno contagiose, e per il virus che ci sta angosciando in queste settimane è stato per ora stimato un R0 molto basso, non superiore a 2,5.
Alla luce di queste considerazioni si possono comprendere meglio le misure messe in atto dalle autorità sanitarie e dalle istituzioni per contenere l'infezione. L'obiettivo è, in ogni caso, cercare di ridurre il valore di R0, oppure, il che è la stessa cosa, cercare abbassare S(t) al di sotto del rapporto di soglia γ/β. Se si raggiunge questo risultato, l'epidemia viene sconfitta. Per farlo, si può agire in diverse direzioni:
1. abbassare il numero S(t) dei suscettibili per sottrarre potenziale terreno di conquista al virus, per esempio sviluppando un vaccino ed effettuando vaccinazioni di massa (ecco perché sono così intensi gli sforzi attuali verso la ricerca di un vaccino contro il nuovo Coronavirus);
2. aumentare il rapporto di soglia γ/β, cosa che si può fare in due soli modi:
a) alzando γ (risultato conseguibile migliorando le terapie e innalzando così la percentuale di guarigioni);
b) abbassando β, che rappresenta la facilità del contagio (risultato conseguibile mediante una migliore educazione igienico-sanitaria e soprattutto riducendo le occasioni di incontro tra le persone - esattamente quello a cui mirano le misure adottate in questi giorni, come la chiusura delle scuole, la sospensione degli eventi, e così' via).
 |
| Due andamenti possibili per un'infezione |
Nella figura a fianco sono mostrati due diversi andamenti possibili per la funzione I(t): ciascuno di essi potrebbe rappresentare la soluzione del sistema di equazioni di Kermack e McKendrick in due diversi casi di infezione.
Chiaramente, l'andamento che presenta il picco corrisponde a un'epidemia in piena regola, molto preoccupante e potenzialmente devastante. Viceversa, l'altra curva, che non fa nemmeno in tempo a salire perché mostra fin dall'inizio una flessione indica un'infezione che passa inosservata perché si esaurisce subito. I modelli SIR ci permettono di distinguere tra queste diverse dinamiche.
Ma c'è una cosa che i modelli SIR non ci possono dire, ed è il numero di vittime che l'infezione può provocare. Se ci avete fatto caso, il modello di Kermack e McKendrick non fa differenza tra individui guariti, deceduti e messi in isolamento: ai fini dell'approccio SIR, in tutti questi casi si verifica una rimozione, nel senso che l'individuo in questione non è più infettivo, e questo basta e avanza per determinare l'andamento della funzione I(t).

Lo specifico parametro legato ai decessi è noto come tasso di letalità dell'infezione: esso è quindi definito come il rapporto tra il numero dei decessi e il numero totale di individui infettivi. Nel corso di un'epidemia, questo indice può variare molto, perché possono modificarsi le condizioni al contorno che rendono la malattia più o meno mortale.
Nella tabella a fianco, possiamo vedere il tasso di letalità stimato per alcune malattie: per alcune è davvero altissimo (evidente il caso dell'Ebola), per altre ovviamente quasi trascurabile (si pensi all'influenza stagionale), mentre il tasso di letalità del nuovo Coronavirus è per adesso stimato attorno al 2%.
Termina qui il breve viaggio di Mr. Palomar nella matematica delle epidemie. Spero che possa giovare per restituire un po' di razionalità e serenità a questi nostri giorni di ansia. Soprattutto, la lezione incoraggiante che possiamo imparare dai modelli SIR è l'inevitabilità dello spegnersi dell'epidemia (ci si augura non ad alto prezzo di decessi): la curva degli infettivi, insomma, prima o poi deve per forza piegarsi verso il basso fino a smorzarsi del tutto.
Come ebbe a dire il grande scrittore portoghese José Saramago nel suo capolavoro Cecità:
Un commentatore televisivo ebbe l’ingegnosità di trovare la metafora giusta quando paragonò l'epidemia, o quel che fosse, a una freccia scagliata verso l’alto, che, nel raggiungere il culmine dell’ascensione, si mantiene per un momento come sospesa, e poi comincia a descrivere l’obbligatoria curva discendente che, a Dio piacendo, e con questa invocazione il commentatore ritornava alla trivialità degli scambi umani e all'epidemia propriamente detta, poi ci penserà la gravità ad accelerare fino alla scomparsa del terribile incubo che ci tormenta (...)









































{kind=link}